In the context of our ArchiMediaL project on Digital Architectural History, a number of student projects explored opportunities and challenges around enriching the colonialarchitecture.eu dataset. This dataset lists buildings and sites in countries outside of Europe that at the time were ruled by Europeans (1850-1970).
Patrick Brouwer wrote his IMM bachelor thesis “Crowdsourcing architectural knowledge: Experts versus non-experts” about the differences in annotation styles between architecture historical experts and non-expert crowd annotators. The data suggests that although crowdsourcing is a viable option for annotating this type of content. Also, expert annotations were of a higher quality than those of non-experts. The image below shows a screenshot of the user study survey.
Rouel de Romas also looked at crowdsourcing , but focused more on the user interaction and the interface involved in crowdsourcing. In his thesis “Enriching the metadata of European colonial maps with crowdsourcing” he -like Patrick- used the Accurator platform, developed by Chris Dijkshoorn. A screenshot is seen below. The results corroborate the previous study that the in most cases the annotations provided by the participants do meet the requirements provided by the architectural historian; thus, crowdsourcing is an effective method to enrich the metadata of European colonial maps.
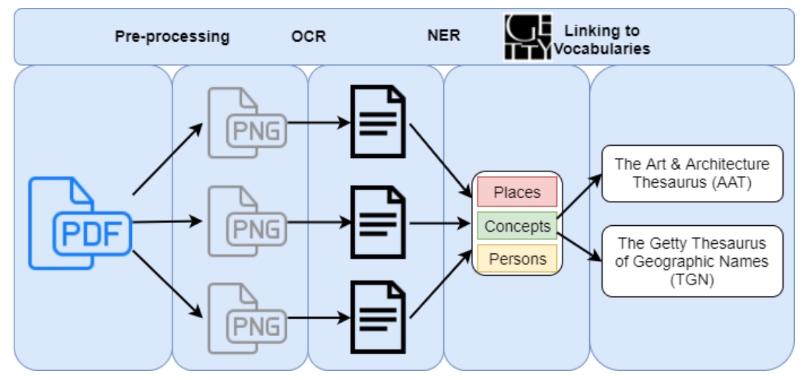
Finally, Gossa Lo looked at automatic enrichment using OCR techniques on textual documents for her Mini-Master projcet. She created a specific pipeline for this, which can be seen in the image below. Her code and paper are available on this Github page:https://github.com/biktorrr/aml_colonialnlp
[This post describes the Master Project work of Information Science students Tim de Bruyn and John Brooks and is based on their theses]
Audiovisual archives adopt structured vocabularies for their metadata management. With Semantic Web and Linked Data now becoming more and more stable and commonplace technologies, organizations are looking now at linking these vocabularies to external sources, for example those of Wikidata, DBPedia or GeoNames.
However, the benefits of such endeavors to the organizations are generally underexplored. For their master project research, done in the form of an internship at the Netherlands Institute for Sound and Vision (NISV), Tim de Bruyn and John Brooks conducted a case study into the benefits of linking the “Common Thesaurus for Audiovisual Archives” (or GTAA) and the general-purpose dataset Wikidata. In their approach, they identified various use cases for user groups that are both internal (Tim) as well as external (John) to the organization. Not only were use cases identified and matched to a partial alignment of GTAA and Wikidata, but several proof of concept prototypes that address these use cases were developed.
For the internal users, three cases were elaborated, including a calendar service where personnel receive notifications when an author of a work has passed away 70 years ago, thereby changing copyright status of the work. This information is retrieved from the Wikidata page of the author, aligned with the GTAA entry (see fig 1 above).
A second internal case involves the new ‘story platform’ of NISV. Here Tim implemented a prototype enduser application to find stories related to the one currently shown to the user, based on persons occuring in that story (fig 2).
The external cases centered around the users of the CLARIAH Media Suite. For this extension, several humanities researchers were interviewed to identify worthwile extensions with Wikidata information. Based on the outcomes of these interviews, John Brooks developed the Wikidata retrieval service (fig 3).
The research presented in the two theses are a good example of User-Centric Data Science, where affordances provided by data linkages are aligned with various user needs. The various tools were evaluated with end users to ensure they match their actual needs. The research was reported in a research paper which will be presented at the MTSR2018 conference: (Victor de Boer, Tim de Bruyn, John Brooks, Jesse de Vos. The Benefits of Linking Metadata for Internal and External users of an Audiovisual Archive. To appear in Proceedings of MTSR 2018 [Draft PDF])
At the DHBenelux 2018 conference, students from the VU minor “Digital Humanities and Social Analytics” presented their final DH in Practice work. In this video, the students talk about their experience in the minor and the internship projects. We also meet other participants of the conference talking about the need for interdisciplinary research.
Last week, I visited the 11th Metadata and Semantics Research Conference (MTSR2017) in Tallinn, Estonia. This conference brings together computer scientists. information scientists and people from the domain of digital libraries to discuss their work in metadata and semantics. The 2017 edition of the conference draws around 70 people which is a great size for a single-track conference with lively discussions. The paper included interesting tracks on Cultural Heritage and Library (meta)data as well as one on Digital Humanities.
On the last day I presented our paper “Enriching Media Collections for Event-based Exploration” [draft pdf], co-authored with the people in the CLARIAH and DIVE+ team working on data enrichment and APIs: Liliana Melgar, Oana Inel Carlos Martinez Ortiz, Lora Aroyo and Johan Oomen. The slides for the presentation can be found here on slideshare. We were very happy to hear that our paper was presented the MTSR2017 Best Paper Award!
In the paper, we present a methodology to publish, represent, enrich, and link heritage collections so that they can be explored by domain expert users. We present four methods to derive events from media object descriptions. We also present a case study where four datasets with mixed media types are made accessible to scholars and describe the building blocks for event-based proto-narrativesin the knowledge graph
The paper was co-authored by Victor de Boer, Oana Inel, Lora Aroyo, Chiel van den Akker, Susane Legene, Carlos Martinez, Werner Helmich, Berber Hagendoorn, Sabrina Sauer, Jaap Blom, Liliana Melgar and Johan Oomen
At the Digital Humanities Benelux 2017 conference, the e-humanities Events working group organized a panel with the titel “A Pragmatic Approach to Understanding and Utilizing Events in Cultural Heritage”. In this panel, researchers from Vrije Universiteit Amsterdam, CWI, NIOD, Huygens ING, and Nationaal Archief presented different views on Events as objects of study and Events as building blocks for historical narratives.
The session was packed and the introductory talks were followed by a lively discussion. From this discussion it became clear that consensus on the nature of Events or what typology of Events would be useful is not to be expected soon. At the same time, a simple and generic data model for representing Events allows for multiple viewpoints and levels of aggregations to be modeled. The combined slides of the panel can be found below. For those interested in more discussion about Events: A workshop at SEMANTICS2017 will also be organized and you can join!
We are excited to announce that DIVE+ has been awarded the Grand Prize at the LODLAM Summit, held at the Fondazione Giorgio Cini this week. The summit brought together ~100 experts in the vibrant and global community of Linked Open Data in Libraries, Archives and Museums. It is organised bi-annually since 2011. Earlier editions were held in the US, Canada and Australia, making the 2017 edition the first in Europe.
The Grand Prize (USD$2,000) was awarded by the LODLAM community. It’s recognition of how DIVE+ demonstrates social, cultural and technical impact of linked data. The Open Data Prize (of USD$1,000) was awarded to WarSampo for its groundbreaking approach to publish open data
Fondazione Giorgio Cini. Image credit: Johan Oomen CC-BY
.Five finalists were invited to present their work, selected from a total of 21 submissions after an open call published earlier this year. Johan Oomen, head of research at the Netherlands Institute for Sound and Vision presented DIVE+ on day one of the summit. The slides of his pitch have been published, as well as the demo video that was submitted to the open call. Next to DIVE+ (Netherlands) and WarSampo (Finland) the finalists were Oslo public library (Norway), Fishing in the Data Ocean (Taiwan) and Genealogy Project (China). The diversity of the finalists is a clear indication that the use of linked data technology is gaining momentum. Throughout the summit, delegates have been capturing the outcomes of various breakout sessions. Please look at the overview of session notes and follow @lodlam on Twitter to keep track.
DIVE+ is an event-centric linked data digital collection browser aimed to provide an integrated and interactive access to multimedia objects from various heterogeneous online collections. It enriches the structured metadata of online collections with linked open data vocabularies with focus on events, people, locations and concepts that are depicted or associated with particular collection objects. DIVE+ is the result of a true interdisciplinary collaboration between computer scientists, humanities scholars, cultural heritage professionals and interaction designers. DIVE+ is integrated in the national CLARIAH (Common Lab Research Infrastructure for the Arts and Humanities) research infrastructure.
Pictured: each day experts shape the agenda for that day, following the OpenSpace format. Image credit: Johan Oomen (cc-by)
DIVE+ is a collaborative effort of the VU University Amsterdam (Victor de Boer, Oana Inel, Lora Aroyo, Chiel van den Akker, Susane Legene), Netherlands Institute for Sound and Vision (Jaap Blom, Liliana Melgar, Johan Oomen), Frontwise (Werner Helmich), University of Groningen (Berber Hagendoorn, Sabrina Sauer) and the Netherlands eScience Centre (Carlos Martinez). It is supported by CLARIAH and NWO.
The LODLAM Challenge was generously sponsored by Synaptica. We would also like to thank the organisers, especially Valentine Charles and Antoine Isaac of Europeana and Ingrid Mason of Aarnet for all of their efforts. LODLAM 2017 has been a truly unforgettable experience for the DIVE+ team.
On Tuesday 13 June 2017, the second CLARIAH Linked Data workshop took place. After the first workshop in September which was very much an introduction to Linked Data to the CLARIAH community, we wanted to organise a more hands-on workshop where researchers, curators and developers could get their hands dirty.
The main goal of the workshop was to introduce relevant tools to novice as well as more advanced users. After a short plenary introduction, we therefore split up the group where for the novice users the focus was on tools that are accompanied by a graphical user interface, like OpenRefine and Gephi; whereas we demonstrated API-based tools to the advanced users, such as the CLARIAH-incubated COW, grlc, Cultuurlink and ANANSI. Our setup, namely to have the participants convert their own dataset to Linked Data and query and visualise, was somewhat ambitious as we had not taken into account all data formats or encodings. Overall, participants were able to get started with some data, and ask questions specific to their use cases.
It is impossible to fully clean and convert and analyse a dataset in a single day, so the CLARIAH team will keep investigating ways to support researchers with their Linked Data needs. For now, you can check out the CultuurLink slidesand tutorial materials from the workshop and keep an eye out on this website for future CLARIAH LOD events.
Last week, the Volkswagen Stiftung-funded “Mixed Methods’ in the Humanities?” programme had its kickoff meeting for all funded projects in in Hannover, Germany. Our ArchiMediaL project on enriching and linking historical architectural and urban image collections was one of the projects funded through this programme and even though our project will only start in September, we already presented our approach, the challenges we will be facing and who will face them (our great team of post-docs Tino Mager, Seyran Khademi and Ronald Siebes). Other interesting projects included analysing of multi-religious spaces on the Medieval World (“Dhimmis and Muslims”); the “From Bach to Beatles” project on representing music and schemata to support musicological scholarship as well as the nice Digital Plato project which uses NLP technologies to map paraphrasing of Plato in the ancient world. An overarching theme was a discussion on the role of digital / quantitative / distant reading methods in humanities research. The projects will run for three years so we have some time to say some sensible things about this in 2020.
An important role in the interpretation of cultural heritage collections is played by ‘historic events’. In the SEMANTiCS workshop Events2017: Understanding Events Semantics in Cultural Heritage, to be held on 11 Sept 2017, we will investigate and discuss challenges around identifying, representing, linking and reasoning about historical events. We invite full papers (8p) as well as short papers (4p) on this topic.
The call for papers is out now. You have until July 10, 2017 to submite your contribution. Contributions can include original research papers, position papers, or papers describing tools, demonstrators or datasets. Accepted contributions will be published on the CEUR-WS website (or equivalent).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}