Happy and suprised to find the first (and so far only) CultuurLink Linking Award in my mail box yesterday! I checked with the nice people over at Spinque.com and it turns out it was a token of appreciation for being a prolific Cultuurlink user 🙂
I think the vocabulary alignment tool is great and easy to work with, so I can recommend it to anyone with a SKOS vocabulary who wants to match it with any of the major cultural thesauri in the ‘Hub’. Thanks to the people at Spinque for the great tool and the nice gesture!
As the Big Data Europe project enters its second year, we’re doing everything we can to make it as simple as possible to get acquainted with the platform which is under development, and facilitate future deployments of our platform to support your Big Data pipelines.
We are therefore happy to introduce this quarterly series of technical webinars, where you can keep track of progress related to our technical developments and demonstrators in each of the seven societal challenges, ask questions, and provide valuable feedback. In addition, we will also cover other important developments in the area which are not necessarily related to our project.
Online Webinar: 02-03-2016, 14:00-15:00 CET
In the first webinar in this series, you will learn about:
the requirements we collected from the 7 Societal Challenges we are addressing
the technical building blocks of our Big Data Platform
how the above will be provided as a generic instance for customisation
an introduction to the 7 selected Pilot partners and the expected outcome
The one hour webinar is run by the Big Data Europe Project and presents inputs and presentations from experts responsible for the architecture, the implementation and the upcoming pilots roll-out. The audience will be given a chance to interact and the top questions will be answered by one of our dedicated technical and domain experts.
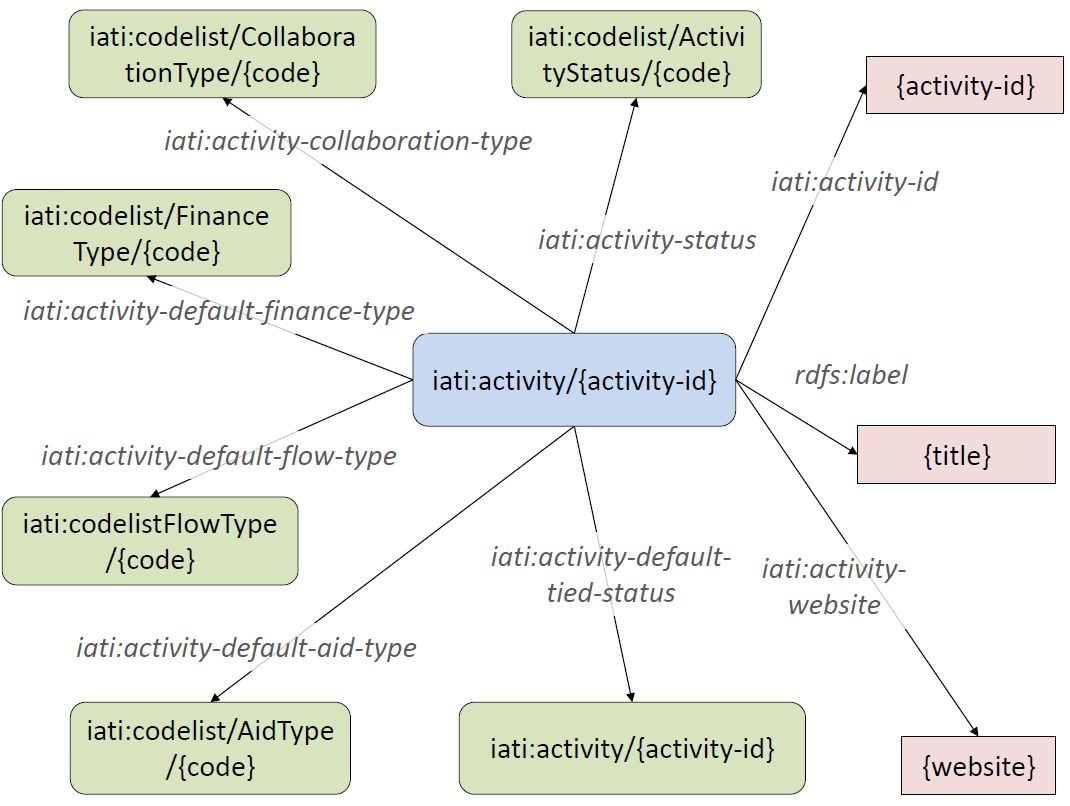
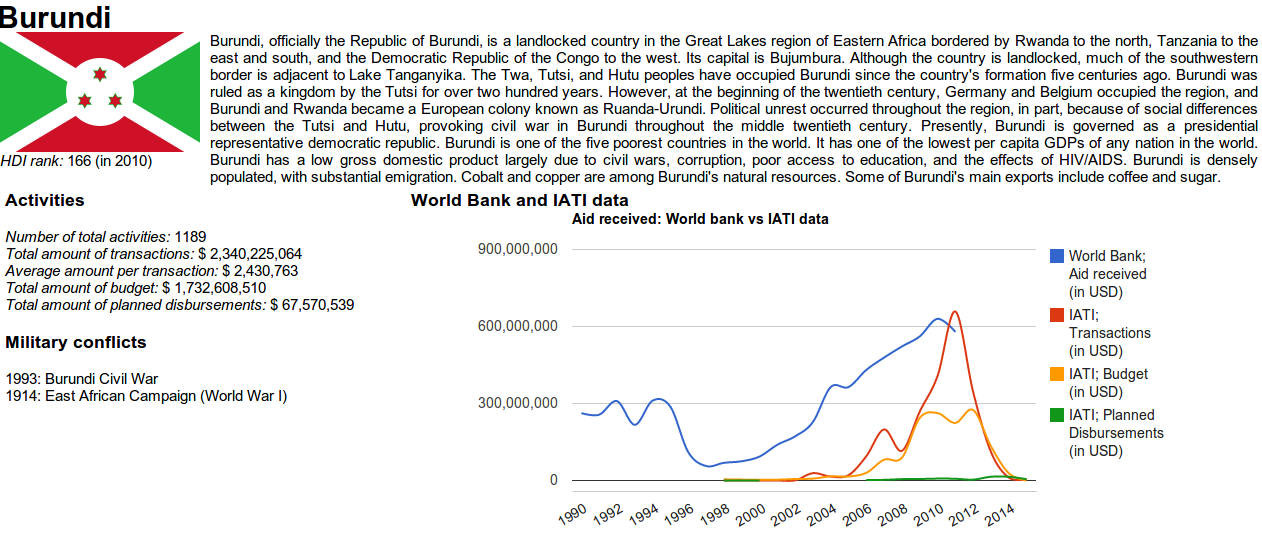
IATI is a multi-stakeholder initiative that seeks to improve the transparecy of development aid and to that end developed an open standard for the publication of aid information. Hundreds of NGOs and governments have registered to the IATI registry by publishing their aid activities in this XML standard. Taking the IATI model as an input, we have created a Linked Data model based on requirements elicitated from qualitative interviews using an iterative requirements engineering methodology. We have converted the IATI open data from a central registry to Linked Data and linked it to various other datasets such as World Bank indicators and DBPedia information. This dataset is made available for re-use at http://semanticweb.cs.vu.nl/iati .
Screenshot of an application bringing together information from multiple datasets
To demonstrate the added value of this Linked Data approach, we have created several applications which combine the information from the IATI dataset and the datasets it was linked to. As a result, we have shown that creating Linked Data for the IATI dataset and linking it to other datasets give new valuable insights in aid transparency. Based on actual information needs of IATI users, we were able to show that linking IATI data adds significant value to the data and is able to fulfill the needs of IATI users.
This year, I co-organized the 5th edition of the Ontology Design Patterens workshop WOP2014 together with Aldo Gangemi, Krzysztof Janowicz and Agnieszka Lawrynowicz. It was co-located with ISWC2014 in Riva del Garda. WOP2014 was a full-day workshop which kicked off with a great keynote from Valentina Presutti. This was followed by presentations of 6 research papers, 2 “pattern” papers and 3 poster presentations. WOP2014 had about 40 attendees, which makes it a very successful edition of this workshop.
During last week’s International Semantic Web Conference (ISWC2014) in Riva del Garda, the DIVE team presented a demonstration prototype of the DIVE tool (which you can play around with live at http://dive.beeldengeluid.nl) . We submitted DIVE to the Open Track of the yearly Semantic Web Challenge for SW tools and applications. Initially, we were invited to give a poster presentation on the first day of the conference and after very positive reviews, we progressed to the challenge final.
For this final we were asked to present the tool and give a live demonstration in front of the ISWC2014 crowd. Apparently the jury appreciated the effort since DIVE was awarded the third prize. The prize included a nice certificate as well as $1000,- sponsored by Elsevier.
This was a real team effort, but I think much of the praise goes to our partners at Frontwise. They built a very cool, very responsive and intuitive User Experience on top of our SPARQL endpoint. Great work! Also thanks to the people at Beeld en Geluid and KB for their assistance with delivering data in a timely fashion and of course the people at VU for their enrichment of the data. Great teamwork everyone! Embedded below you find the poster and the presentation. The paper is found here.
Linking historical datasets and making them available for the Web has increasingly become a subject of research in the field of digital humanities. In the Netherlands, history is intimately related to the maritime activity because it has been essential in the development of economic, social and cultural aspects of Dutch society. As such an important sector, it has been well documented by shipping companies, governments, newspapers and other institutions.
In this master project we assume that, given the importance of maritime activity in every day life in the XIX and XX centuries, announcements on the departures and arrivals of ships or mentions of accidents or other events, can be found in newspapers.
We have taken a two-stage approach: first, an heuristic-based method for record linkage and then machine-learning algorithms for article classification to be used for filtering in combination with domain features. Evaluation of the linking method has shown that certain domain features were indicative of mentions of ships in newspapers. Moreover, the classifier methods scored near perfect precision in predicting ship related articles.
Enriching historical ship records with links to newspaper archives is significant for the digital history community since it connects two datasets that would have otherwise required extensive annotating work and man hours to align. Our work is part of the Dutch Ships and Sailors Linked Data Cloud project. Check out Andrea’s thesis[pdf].
[This post was written by Rianne Nieland. It describes her MSc. project supervised by myself]
People in developing countries cannot access information on the Web, because they have no Internet access and are often low literate. A solution could be to provide voice-based access to data on the Web by using the GSM network.
In my master project I have investigated how to make general-purpose data sets efficiently available using voice interfaces for GSM. To achieve this, I have developed two voice interfaces, one for Wikipedia and one for DBpedia. I have made two voice interfaces with two different kinds of input data sources, namely normal web data and Linked Data, to be able to compare them.
To develop the two voice interfaces, I first did requirements elicitation from literature and developed a user interface and conversion algorithms for Wikipedia and DBpedia concepts. With user tests the users evaluated the two voice interfaces, to be able to compare them on speed, error rate and usability.
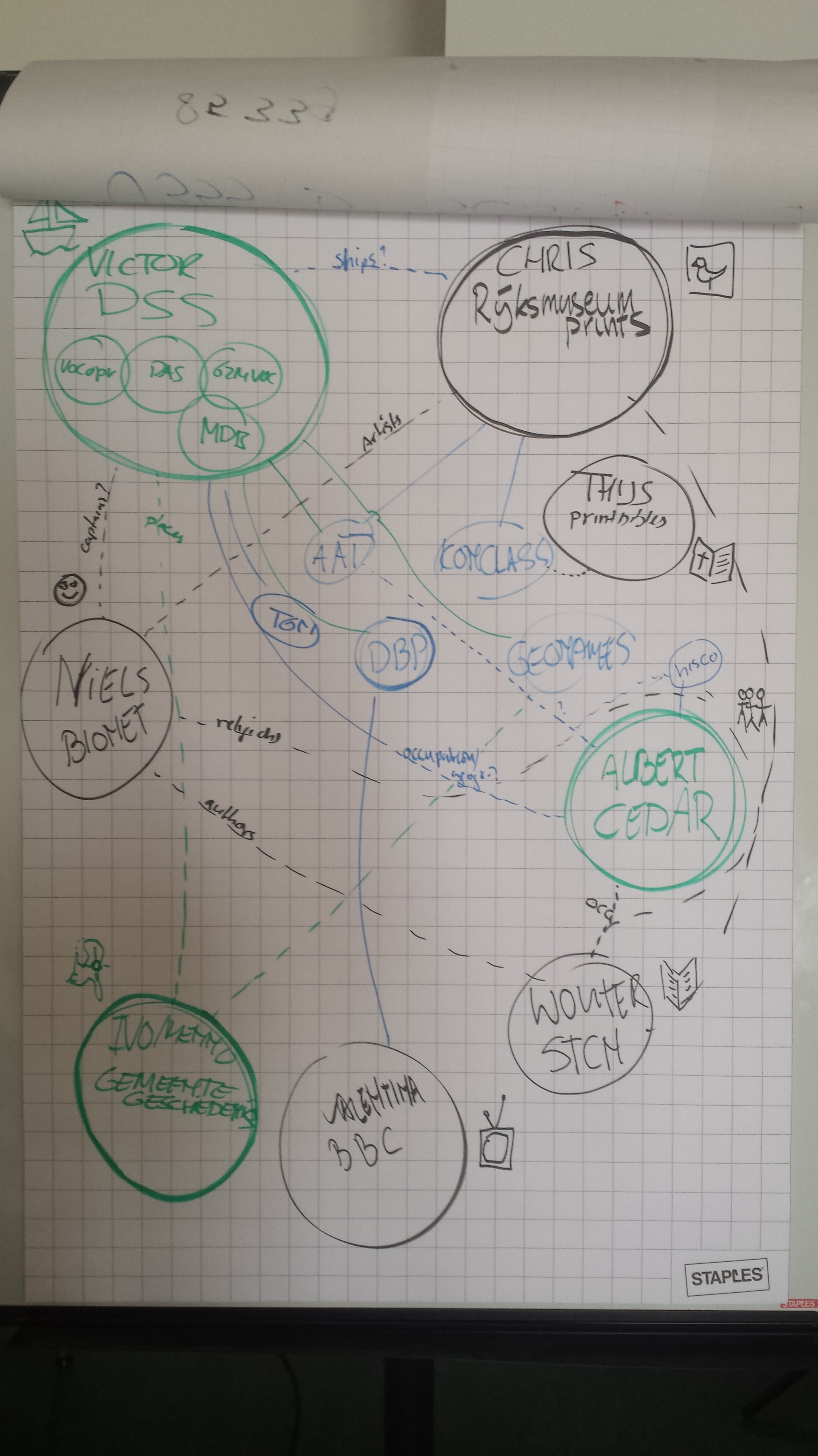
5000+ links from people in the BiographyNet RDF data to people in the Rijksmuseum RDF data.
2 links from Dutch Ships and Sailors to Rijksmuseum collections
61 links from Dutch Ships and Sailors Ranks to CEDAR Hisco ‘occupation’ URIs were made
1320 links of CEDAR municipalities (by Amsterdamse Code) to gemeentegeschiedenis.nl municipalities
33 links of ICONCLASS (used by Rijksmuseum) to HISCO occupations
We hope to expand this datacloud in the near future and show the added value of such an interconnected digital history cloud for historical research and the general public. You can read more at Albert’s blog or on the blog of Ivo Zandhuis’ Hic Sunt Leones
DOWNSCALE 2013, the 2nd international workshop on downscaling the Semantic Web was held on 19-9-2013 in Geneva, Switzerland and was co-located with the Open Knowledge Conference 2013. The workshop seeks to provide first steps in exploring appropriate requirements, technologies, processes and applications for the deployment of Semantic Web technologies in constrained scenarios, taking into consideration local contexts. For instance, making Semantic Web platforms usable under limited computing power and limited access to Internet, with context-specific interfaces.
Downscale group picture
The workshop accepted three full papers after peer-review and featured five invited abstracts. in his keynote speech, Stephane Boyera of SBC4D gave a very nice overview of the potential use of Semantic Web for Social & Economic Development. The accepted papers and abstracts can be found in the downscale2013 proceedings, which will also appear as part of the OKCon 2013 Open Book.
We broadcast the whole workshop live on the web, and you can actually watch the whole thing (or fragments) via the embedded videos below.
[youtube=http://www.youtube.com/watch?v=r4pqVUeZMDI&w=560&h=315]
[youtube=http://www.youtube.com/watch?v=y2RPnxFrWX0&w=560&h=315]
After the presentations, we had fruitful discussions about the main aspects of ‘downscaling’. The consensus seemed to be that Downscaling involved the investigation and usage of Semantic Web technologies and Linked Data principles to allow for data, information and knowledge sharing in circumstances where ‘mainstream’ SW and LD is not feasible or simply does not work. These circumstances can be because of cultural, technical or physical limitations or because of natural or artificial limitations.
The figure illustrates a first attempt to come to a common architecture. It includes three aspects that need to be considered when thinking about data sharing in exceptional circumstances:
Hardware/ Infrastructure. This aspect includes issues with connectivity, low resource hardware, unavailability, etc.
Interfaces. This concerns the design and development of appropriate interfaces with respect to illiteracy of users or their specific usage. Building human-usable interfaces is a more general issue for Linked data.
Pragmatic semantics. Developing LD solutions that consider which information is relevant in which (cultural) circumstances is crucial to its success. This might include filtering of information etc.
The right side of the picture illustrates the downscaling stack.
Last week, Knud Moeller from datalysator and I were invited to give a set of lectures about Linked Data in the CSWS 2013 summer school in Shanghai, China. As far as we are concerned the summer school was a success. About 60 students received three mornings worth of lectures about the principles and practice of Linked Data from the two of us. In the afternoon, they heard talks about Semantic Web efforts from the likes of Baidu and Google.
Because of the unavailability/-reachability of twitter, facebook, slideshare and wordpress in China, the lecture materual can be found are online as pdfs through a HTML page at my VU homepage.









 Last week, Knud Moeller from
Last week, Knud Moeller from 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}