As supervisor of many MSc and BSc theses, I find myself giving writing tips and guidelines quite often. Inspired by Jan van Gemert’s guidelines, I compiled my own document with tips and guidelines for writing an CS/AI/IS bachelor or master thesis. These are things that I personally care about and other lecturers might have different ideas. Also, this is by no means a complete list and I will use it as a living document. You can find it here: https://tinyurl.com/victorthesiswriting
This Monday, Accenture and the UN organized the Knowledge Graphs for Social Good workshop, part of the Knowledge Graph conference. My submission to this workshop “Knowledge Graphs for the Rural Poor” was about ICT for Development research previously done within the FP7 VOICES in collaboration with students. In the contribution, we argue that there are three challenges to make Knowledge Graphs relevant and accessible for the Rural Poor.
Make KGs usable in low-resource, low-connectivity contexts
Make KGs accessible for users with various (cultural) backgrounds and levels of literacy;
Develop knowledge sharing cases and applications relevant for the rural poor
I contributed to a (Dutch) article written in response to the new European AI guidelines. The article, written by members of the Cultural AI lab, argues that we need both cultural data and cultural understanding to build truly responsible AI. It has been published in the Public Spaces blog.
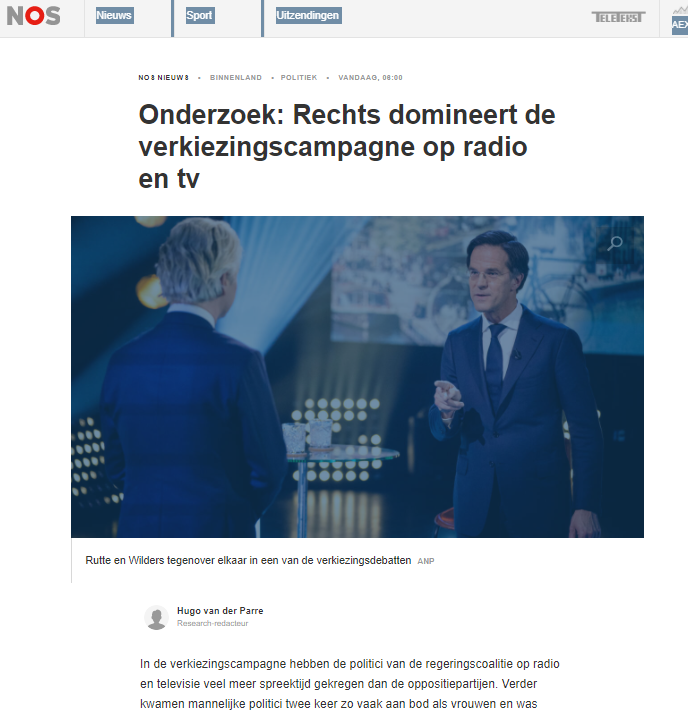
It was great to see that one of this year’s Digital Humanities in Practice projects lead to a conversation between the students in that project Helene Ayar and Edith Brooks, their external supervisors Willemien Sanders (UU) and Mari Wigham (NISV) and an advisor for another project André Krouwel (VU). That conversation resulted in original research and CLARIAH MediaSuite data story “‘Who’s speaking?’- Politicians and parties in the media during the Dutch election campaign 2021” where the content of news programmes was analysed for politicians’ names, their gender and party affiliation.
This year’s edition of the VU Digital Humanities in Practice course was of course a virtual one. In this course, students of the Minor Digital Humanities and Social Analytics put everything that they have learned in that minor in practice, tackling a real-world DH or Social Analytics challenge. As in previous years, this year we had wonderful projects provided and supervised by colleagues from various institutes. We had projects related to the Odissei and Clariah research infrastructures, projects supervised by KNAW-HUC, Stadsarchief Amsterdam, projects from Utrecht University, UvA, Leiden University and our own Vrije Universiteit. We had a project related to Kieskompas and even a project supervised by researchers from Bologna University. A wide variety of challenges, datasets and domains! We would like to thank all the supervisors and the students on making this course a success.
The compilation video below shows all the projects’ results. It combines 2-minute videos produced by each of the 10 student groups.
After a very nice virtual poster session, everybody got to vote on the Best Poster Award. The winners are group 3, whose video you can also see in the video above. Below we list all the projects and the external supervisors.
1
Extracting named entities from Social Science data.
At this year’s Metadata and Semantics Research Conference (MTSR2020), I just presented our work on Linked Data Scopes: an ontology to describe data manipulation steps. The paper was co-authored with Ivette Bonestroo, one of our Digital Humanities minor students as well as Rik Hoekstra and Marijn Koolen from KNAW-HUC. The paper builds on earlier work by the latter two co-authors and was conducted in the context of the CLARIAH-plus project.
This figure shows envisioned use of the ontology: scholarly output is not only the research paper, but also an explicit data scope. This data scope includes (references to) datasets.
With the rise of data driven methods in the humanities, it becomes necessary to develop reusable and consistent methodological patterns for dealing with the various data manipulation steps. This increases transparency, replicability of the research. Data scopes present a qualitative framework for such methodological steps. In this work we present a Linked Data model to represent and share Data Scopes. The model consists of a central Data scope element, with linked elements for data Selection, Linking, Modeling, Normalisation and Classification. We validate the model by representing the data scope for 24 articles from two domains: Humanities and Social Science.
[This blog post is based on the Master thesis Information Sciences of Bram Schmidt, conducted at the KNAW Humanities cluster and IISG. It reuses text from his thesis]
Place names (toponyms) are very ambiguous and may change over time. This makes it hard to link mentions of places to their corresponding modern entity and coordinates, especially in a historical context. We focus on historical Toponym Disambiguation approach of entity linking based on identified context toponyms.
The thesis specifically looks at the American Gazetteer. These texts contain fundamental information about major places in its vicinity. By identifying and exploiting these tags, we aim to estimate the most likely position for the historical entry and accordingly link it to its corresponding contemporary counterpart.
Example of a toponym in the Gazetteer
Therefore, in this case study, Bram Schmidt examined the toponym recognition performance of state-of-the-art Named Entity Recognition (NER) tools spaCy and Stanza concerning historical texts and we tested two new heuristics to facilitate efficient entity linking to the geographical database of GeoNames.
Experiments with different geo-distance heuristics show that indeed this can be used to disambiguate place names.
We tested our method against a subset of manually annotated records of the gazetteer. Results show that both NER tools do function insufficiently in their task to automatically identify relevant toponyms out of the free text of a historical lemma. However, exploiting correctly identified context toponyms by calculating the minimal distance among them proves to be successful and combining the approaches into one algorithm shows improved recall score.
From November 1 2020, we are collaborating on connecting tangible and intangible heritage through knowledge graphs in the new Horizon2020 project “InTaVia“.
To facilitate access to rich repositories of tangible and intangible asset, new technologies are needed to enable their analysis, curation and communication for a variety of target groups without computational and technological expertise. In face of many large, heterogeneous, and unconnected heritage collections we aim to develop supporting technologies to better access and manage in/tangible CH data and topics, to better study and analyze them, to curate, enrich and interlink existing collections, and to better communicate and promote their inventories.
tangible and intagible heritage (img from project proposal)
Our group will contribute to the shared research infrastructure and will be responsible for developing a generic solution for connecting linked heritage data to various visualization tools. We will work on various user-facing services and develop an application shell and front-end for this connection be responsible for evaluating the usability of the integrated InTaVia platform for specific users. This project will allow for novel user-centric research on topics of Digital Humanities, Human-Computer interaction and Linked Data service design.
[This blog post was written by Nizar Hirzalla and describes his VU Master AI project conducted at the Koninklijke Bibliotheek (KB), co-supervised by Sara Veldhoen]
Authorship attribution is the process of correctly attributing a publication to its corresponding author, which is often done manually in real-life settings. This task becomes inefficient when there are many options to choose from due to authors having the same name. Authors can be defined by characteristics found in their associated publications, which could mean that machine learning can potentially automate this process. However, authorship attribution tasks introduce a typical class imbalance problem due to a vast number of possible labels in a supervised machine learning setting. To complicate this issue even more, we also use problematic data as input data as this mimics the type of available data for many institutions; data that is heterogeneous and sparse of nature.
The thesis searches for answers regarding how to automate authorship attribution with its known problems and this type of input data, and whether automation is possible in the first place. The thesis considers children’s literature and publications that can have between 5 and 20 potential authors (due to having the same exact name). We implement different types of machine learning methodologies for this method. In addition, we consider all available types of data (as provided by the National Library of the Netherlands), as well as the integration of contextual information.
Furthermore, we consider different types of computational representations for textual input (such as the title of the publication), in order to find the most effective representation for sparse text that can function as input for a machine learning model. These different types of experiments are preceded by a pipeline that consists out of pre-processing data, feature engineering and selection, converting data to other vector space representations and integrating linked data. This pipeline shows to actively improve performance when used with the heterogeneous data inputs.
Implemented neural network architectures for TFIDF (left) and Word2Vec (right) based text classification
Ultimately the thesis shows that automation can be achieved in up to 90% of the cases, and in a general sense can significantly reduce costs and time consumption for authorship attribution in a real-world setting and thus facilitate more efficient work procedures. While doing so, the thesis also finds the following key notions:
Between comparison of machine learning methodologies, two methodologies are considered: author classification and similarity learning. Author classification grants the best raw performance (F1. 0.92), but similarity learning provides the most robust predictions and increased explainability (F1. 0.88). For a real life setting with end users the latter is recommended as it presents a more suitable option for integration of machine learning with cataloguers, with only a small hit to performance.
The addition of contextual information actively increases performance, but performance depends on the type of information inclusion. Publication metadata and biographical author information are considered for this purpose. Publication metadata shows to have the best performance (predominantly the publisher and year of publication), while biographical author information in contrast negatively affects performance.
We consider BERT, word embeddings (Word2Vec and fastText) and TFIDF for representations of textual input. BERT ultimately grants the best performance; up to 200% performance increase when compared to word embeddings. BERT is a sophisticated language model with an applied transformer, which leads to more intricate semantic meaning representation of text that can be used to identify associated authors.
Based on surveys and interviews, we also find that end users mostly attribute importance to author related information when engaging in manual authorship attribution. Looking more in depth into the machine learning models, we can see that these primarily use publication metadata features to base predictions upon. We find that such differences in perception of information should ultimately not lead to negative experiences, as multiple options exist for harmonizing both parties’ usage of information.
Summary of the final performances of the best performing models from the differing implemented methodologies
This year’s SEMANTiCS conference was a weird one. As so many other conferences, we had to improvise to deal with the COVID-19 restrictions around travel and event organization. With the help of many people behind the scenes -including the wonderful program chairs Paul Groth and Eva Blomqvist- , we did have a relatively normal reviewing process for the Research and Innovation track. In the end, 8 papers were accepted for publication in this year’s proceedings. The authors were then asked to present their work in pre-recorded videos. These were shown in a very nice webinar, together with contributions from industry. All in all, we feel this downscaled version of Semantics was quite successful.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}