The CLARIN framework commissioned the production of dissemmination videos showcasing the outcomes of the individual CLARIN projects. One of these projects was the Dutch Ships and Sailors project, a collaboration between VU Computer Science, VU humanities and the Huygens Institute for National History. In this project, we developed a heterogeneous linked data cloud connecting many different maritime databases. This data cloud allows for new types of integrated browsing and new historical research questions. In the video, we (Victor de Boer together with historians Jur Leinenga and Rik Hoekstra) explain how the data cloud was formed and how it can be used by maritime historians.
This is a nice companion piece to the more technical description of the dataset which was published in the proceedings of ISWC 2014. The new version highlights more the general setup of the project and the considerations and innovations of the project from a historical point of view.
New datacloudSince submission of this ‘mid-term project description’, the DSS data cloud has been expanding, and the ‘development’ version of the triple store now hosts six datasets thanks to the work of Jeroen Entjes (see the datacloud figure).
[This post was written by Jeroen Entjes and describes his Msc Thesis research]
The Dutch maritime supremacy during the Dutch Golden Age has had a profound influence on the modern Netherlands and possibly other places around the globe. As such, much historic research has been done on the matter, facilitated by thorough documentation done by many ports of their shipping. As more and more of these documentations are digitized, new ways of exploring this data are created.
Screenshot showing an entry from the Elbing website
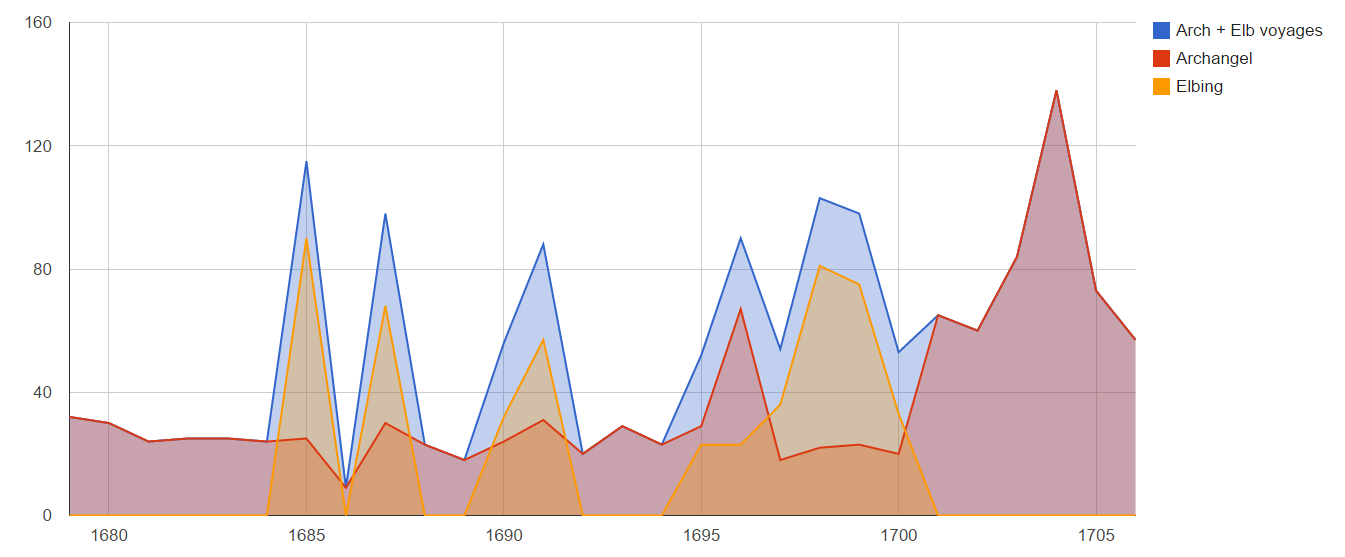
This master project uses one such way. Based on the Dutch Ships and Sailors project digitized maritime datasets have been converted to RDF and published as Linked Data. Linked Data refers to structured data on the web that is published and interlinked according to a set of standards. This conversion was done based on requirements for this data, set up with historians from the Huygens ING Institute that provided the datasets. The datasets chosen were those of Archangel and Elbing, as these offer information of the Dutch Baltic trade, the cradle of the Dutch merchant navy that sailed the world during the Dutch Golden Age.
Along with requirements for the data, the historians were also interviewed to gather research questions that combined datasets could help solve. The goal of this research was to see if additional datasets could be linked to the existing Dutch Ships and Sailors cloud and if such a conversion could help solve the research questions the historians were interested in.
Data visualization showing shipping volume of different datasets.
As part of this research, the datasets have been converted to RDF and published as Linked Data as an addition to the Dutch Ships and Sailors cloud and a set of interactive data visualizations have been made to answer the research questions by the historians. Based on the conversion, a set of recommendations are made on how to convert new datasets and add them to the Dutch Ships and Sailors cloud. All data representations and conversions have been evaluated by historians to assess the their effectiveness.
This year’s third issue of E-Data and Research magazine features an article about the Dutch Ships and Sailors project. The article (in Dutch) describes how our project provides new ways of interacting with Dutch maritime data. So far, four datasets are present in the DSS data cloud but we are currently extending the dataset with two new datasets. More on that later…
In the same issue, there is an article about the workshop around newspaper data as provided by the National Library. This includes a picture of me presenting the DIVE project.
Today, the TPDL (International Conference on Theory and Practice of Digital Libraries) results came in and both papers on which I am a co-author got accepted. Today is a good day 🙂 The first paper, we present work done during my stay at Netherlands Institute for Sound and Vision on automatic term extraction from subtitles. The interesting thing about this paper was that it was mainly how these algorithms were functioning in a ‘real’ context, that is within a larger media ecosystem. The paper was co-authored with Roeland Ordelman and Josefien Schuurman.
Last week, I presented our work on the Verrijkt Koninkrijk project at the E-humanities workshop in the Soeterbeeck monastery which was organised by the university of Nijmegen and the e-humanities group of KNAW.
It was a very pleasant get-together with some nice talks and hands on sessions. Alice Dijkstra from NWO presented a number of opportunities for getting funding for e-humanities projects. She mentioned some obvious candidates (vernieuwingsimpuls,…) and some less obvious ones (the hopefully upcoming CLARIAH programme, which would continue CLARIN and DARIAH).
The two hands on sessions were nice but showed that there is a more general issue with e-humanities that ‘nice tools’ are being developed but that these tools remain solutions to a single problem. Next to that they are either nice from a computer science or from a historical science viewpoint but it is hard to do exciting comp.science and historical science at the same time. This is reenforced by the issue that historical scientists rarely know what type of tools they want at the beginning of a project. A more interactive and cyclical approach makes sense for both parties. The BiographyNet idea of putting the researchers from different backgrounds in the same room would be one solution. The other in my view is the development of more general-purpose query environments .
In my poster presentation I showed how I tried to do that with Verrijkt Koninkrijk and I think for a more or less generic data analysis interface is also a good idea.
You can download the VK poster Abstract as well as the actual Poster.


 This year’s third
This year’s third 
 The first paper, we present work done during my stay at
The first paper, we present work done during my stay at 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}